数据模型设计
多年以来,关系型数据库已经成为了企业数据管理的基础,很多工程师对于关系模型和 6 个范式都比较了解,但是如今来构建和运行一个应用,随着数据来源的越发多样和用户量的不断增长,关系数据库的限制逐渐成为业务的瓶颈,因此越来越多的公司开始向其他 NoSQL 数据库进行迁移。
LeanCloud 的数据存储后台大量采用了 MongoDB 这种文档数据库来存储结构化数据,正因如此我们才能提供面向对象的、海量的、无需创建数据表结构即存即用的存储能力。从传统的关系型数据库转换到 LeanCloud 或者 MongoDB 存储系统,最基础的改变就是「数据建模 Schema 设计」。
首先来梳理一下关系型数据库、MongoDB 和 LeanCloud 数据存储的对应术语:
| RDBMS | MongoDB | LeanCloud 数据存储 |
|---|---|---|
| Database | Database | Application |
| Table | Collection | Class |
| Row | Document | Object |
| Index | Index | Index |
| JOIN | Embedded,Reference | Embedded Object, Pointer |
在 LeanCloud 上进行数据建模设计需要数据架构师、开发人员和 DBA 在观念上做一些转变:之前是传统的关系型数据模型,所有数据都会被映射到二维的表结构「行」和「列」;现在是丰富、动态的对象模型,即 MongoDB 的「文档模型」,包括内嵌子对象和数组。
文档模型
后文中我们有时候采用 LeanCloud 数据存储的核心概念 Object(对象),有时候提到 MongoDB 中的名词 Document(文档),它们是等同的。
我们现在使用的大部分数据都有比较复杂的结构,用「JSON 对象」来建模比用「表」会更加高效。通过内嵌子对象和数组,JSON 对象可以和应用层的数据结构完全对齐。这对开发者来说,会更容易将应用层的数据映射到数据库里的对象。相反,将应用层的数据映射到关系数据库的表,则会降低开发效率。而比较普遍的增加额外的对象关系映射(ORM)层的做法,也同时降低了 schema 扩展和查询优化的灵活性,引入了新的复杂度。
例如,在 RDBMS 中有父子关系的两张表,通常就会变成 LeanCloud 里面含有内嵌子对象的单文档结构。以下图的数据为例:
PERSON 表
| Person_ID | Surname | First_Name | City |
|---|---|---|---|
| 0 | 柳 | 红 | 伦敦 |
| 1 | 杨 | 真 | 北京 |
| 2 | 王 | 新 | 苏黎世 |
CAR 表
| Car_ID | Model | Year | Value | Person_ID |
|---|---|---|---|---|
| 101 | 大众迈腾 | 2015 | 180000 | 0 |
| 102 | 丰田汉兰达 | 2016 | 240000 | 0 |
| 103 | 福特翼虎 | 2014 | 220000 | 1 |
| 104 | 现代索纳塔 | 2013 | 150000 | 2 |
RDBMS 中通过 Person_ID 域来连接 PERSON 表和 CAR 表,以此支持应用中显示每辆车的拥有者信息。使用文档模型,通过内嵌子对象和数组可以将相关数据提前合并到一个单一的数据结构中,传统的跨表的行和列现在都被存储到了一个文档内,完全省略掉了 join 操作。
换成 LeanCloud 来对同样的数据建模,则允许我们创建这样的 schema:一个单一的 Person 对象,里面通过一个子对象数组来保存该用户所拥有的每一部 Car,例如:
{
"first_name":"红",
"surname":"柳",
"city":"伦敦",
"location":[
45.123,
47.232
],
"cars":[
{
"model":"大众迈腾",
"year":2015,
"value":180000
},
{
"model":"丰田汉兰达",
"year":2016,
"value":240000
}
]
}
文档数据库里的一篇文档,就相当于 LeanCloud 平台里的一个对象。这个例子里的关系模型虽然只由两张表组成(现实中大部分应用可能需要几十、几百甚至上千张表),但是它并不影响我们思考数据的方式。
为了更好地展示关系模型和文档模型的区别,我们用一个博客平台来举例。从下图中可以看出,依赖 RDBMS 的应用需要 join 五张不同的表来获得一篇博客的完整数据,而在 LeanCloud 中所有的博客数据都包含在一个文档中,博客作者和评论者的用户信息则通过一个到 User 的引用(指针)进行关联。
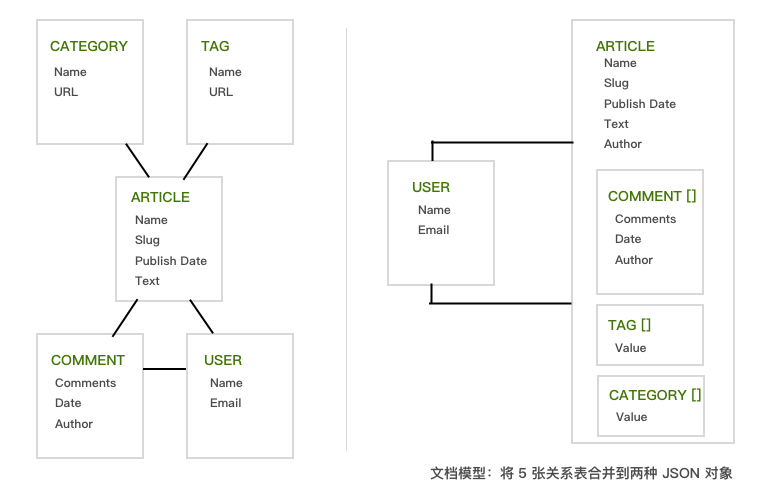
文档模型的优点
除了数据表现更加自然之外,文档模型还有性能和扩展性方面的优势:
- 通过单一调用即可获得完整的文档,避免了多表 join 的开销。LeanCloud 的 Object 物理上作为一个单一的块进行存储,只需要一次内存或者磁盘的读操作即可。RDBMS 与此相反,一个 join 操作需要从不同地方多次读取操作才可完成。
- 文档是自包含的,将数据库内容分布到多个节点(也叫 Sharding)会更简单,同时也更容易通过普通硬件的水平扩展获得更高性能。DBA 们不再需要担心跨节点进行 join 操作可能带来的性能恶化问题。
定义文档 Schema
应用的数据访问模式决定了 schema 设计,因此我们需要特别明确以下几点:
- 数据库读写操作的比例以及是否需要重点优化某一方的性能;
- 对数据库进行查询和更新的操作类型;
- 数据生命周期和文档的增长率;
以此来设计更合适的 schema 结构。
对于普通的「属性名:值」来说,设计比较简单,和 RDBMS 中平坦的表结构差别不大。对于「一对一」或「一对多」的关系会很自然地考虑使用内嵌对象:
- 数据「所有」和「包含」的关系,都可以通过内嵌对象来进行建模。
- 同时,在架构上也可以把那些经常需要同时、原子改动的属性作为一个对象嵌入到一个单独的属性中。
例如,为了记录每个学生的家庭住址,我们可以把住址信息作为一个整体嵌入 Student 类里面。
- .NET
- Java
- Objective-C
- Swift
- Flutter
- JavaScript
- Python
- PHP
- Go
LCObject studentTom = new LCObject("Student");
studentTom["name"] = "Tom";
var addr = new Dictionary<string, object>();
addr["city"] = "北京";
addr["address"] = "西城区西长安街 1 号";
addr["postcode"] = "100017";
studentTom["address"] = addr;
await studentTom.Save();
AVObject studentTom = new AVObject("Student");
studentTom.put("name", "Tom");
HashMap<Object, Object> addr = new HashMap<>();
addr.put("city", "北京");
addr.put("address", "西城区西长安街 1 号");
addr.put("postcode", "100017");
studentTom.put("address", addr);
studentTom.saveInBackground().subscribe(new Observer<AVObject>() {
public void onSubscribe(Disposable disposable) {}
public void onNext(AVObject studentTom) {
// 成功保存之后,执行其他逻辑
System.out.println("保存成功。objectId:" + studentTom.getObjectId());
}
public void onError(Throwable throwable) {
// 异常处理
}
public void onComplete() {}
});
LCObject *studentTom = [LCObject objectWithClassName:@"Student"];
[studentTom setObject:@"Tom" forKey:@"name"];
NSDictionary *addr = [NSDictionary dictionaryWithObjectsAndKeys:
@"北京", @"city",
@"西城区西长安街 1 号", @"address",
@"100017", @"postcode",
nil];
[studentTom setObject:addr forKey:@"address"];
[studentTom saveInBackgroundWithBlock:^(BOOL succeeded, NSError *error) {
if (succeeded) {
// 成功保存之后,执行其他逻辑
NSLog(@"保存成功。objectId:%@", studentTom.objectId);
} else {
// 异常处理
}
}];
do {
let studentTom = LCObject(className: "Student")
try studentTom.set("name", "Tom")
try studentTom.set("address", [
"city" : "北京",
"address" : "西城区西长安街 1 号",
"postcode" : "100017"
]
_ = studentTom.save { result in
switch result {
case .success:
// 成功保存之后,执行其他逻辑
break
case .failure(error: let error):
// 异常处理
print(error)
}
}
} catch {
print(error)
}
// 构建对象
LCObject studentTom = LCObject('Student');
studentTom['name'] = 'Tom';
Map<String, dynamic> address = {
'city': '北京',
'address': '西城区西长安街 1 号',
'postcode': '100017'
};
studentTom['address'] = address;
await studentTom.save();
// 学生 Tom
const studentTom = new AV.Object('Student');
studentTom.set('name', 'Tom');
const addr = { "city": "北京", "address": "西城区西长安街 1 号", "postcode":"100017" };
studentTom.set('address', addr);
studentTom.save().then((studentTom) => {
// 成功保存之后,执行其他逻辑
console.log(`保存成功。objectId:${studentTom.id}`);
}, (error) => {
// 异常处理
});
student_tom = leancloud.Object.extend("Student")()
student_tom.set('name', 'Tom')
addr = { "city": "北京", "address": "西城区西长安街 1 号", "postcode":"100017" }
student_tom.set('address', addr)
student_tom.save()
$studentTom = new LeanObject("Student");
$studentTom->set("name", "Tom");
$addr = array("city" => "北京", "address" => "西城区西长安街 1 号", "postcode" => "100017");
$studentTom->set("address", $addr);
$studentTom->save();
但并不是所有的一对一关系都适合内嵌的方式,对下面的情况后文介绍的「引用」(等同于 MongoDB 的 reference)方式会更加合适:
- 一个对象被频繁地读取,但是内嵌的子对象却很少会被访问。
- 对象的一部分属性频繁地被更新,数据大小持续增长,但是剩下的一部分属性基本稳定不变。
- 对象大小超过了 LeanCloud 当前最大 16 MB 限制。
接下来我们重点讨论一下在 LeanCloud 上如何通过「引用」机制来实现复杂的关系模型。
数据对象之间存在 3 种类型的关系:「一对一」将一个对象与另一个对象关联,「一对多」是一个对象关联多个对象,「多对多」则用来实现大量对象之间的复杂关系。
我们支持 3 种方式来构建对象之间的关系,这些都是通过 MongoDB 的文档引用来实现的:
- Pointers(适合一对一、一对多关系)
- 中间表(多对多)
Arrays(一对多、多对多)不建议使用,请参考 何时使用数组。
一对多关系
Pointers 存储
中国的「省份」与「城市」具有典型的一对多的关系。深圳和广州(城市)都属于广东省(省份),而朝阳区和海淀区(行政区)只能属于北京市(直辖市)。广东省对应着多个一级行政城市,北京对应着多个行政区。下面我们使用 Pointers 来存储这种一对多的关系。
为了表述方便,后文中提及城市都泛指一级行政市以及直辖市行政区,而省份也包含了北京、上海等直辖市。
- .NET
- Java
- Objective-C
- Swift
- Flutter
- JavaScript
- Python
- PHP
- Go
LCObject guangZhou = new LCObject("City");
guangZhou["name"] = "广州";
LCObject guangDong = new LCObject("Province");
guangDong["name"] = "广东";
guangZhou["dependent"] = guangDong;
// 广东无需单独保存,因为在保存广州时自动保存了广东
await guangZhou.Save();
AVObject guangZhou = new AVObject("City");
guangZhou.put("name", "广州");
AVObject guangDong = new AVObject("Province");
guangDong.put("name", "广东");
guangZhou.put("dependent", guangDong);
guangZhou.saveInBackground().subscribe(new Observer<AVObject>() {
@Override
public void onSubscribe(Disposable d) {
}
@Override
public void onNext(AVObject guangZhou) {
// 广州、广东保存成功(广东无需单独保存)
}
@Override
public void onError(Throwable e) {
}
@Override
public void onComplete() {
}
});
LCObject *GuangZhou = [LCObject objectWithClassName:@"City"];
[GuangZhou setObject:@"广州" forKey:@"name"];
LCObject *GuangDong = [LCObject objectWithClassName:@"Province"];
[GuangDong setObject:@"广东" forKey:@"name"];
[GuangZhou setObject:GuangDong forKey:@"dependent"];
[GuangZhou saveInBackgroundWithBlock:^(BOOL succeeded, NSError *error) {
if (succeeded) {
// 广州、广东保存成功(广东无需单独保存)
}
}];
do {
let guangZhou = LCObject(className: "City")
try guangZhou.set("name", value:"广州")
let guangDong = LCObject(className: "Province")
try guangDong.set("name", value:"广东")
try guangZhou.set("dependent", guangDong)
_ = guangZhou.save { result in
switch result {
case .success:
// 广州、广东保存成功(广东无需单独保存)
break
case .failure(error: let error):
// 异常处理
print(error)
}
}
} catch {
print(error)
}
LCObject guangZhou = LCObject('City');
guangZhou['name'] = '广州';
LCObject guangDong = LCObject('Province');
guangDong['name'] = '广东';
guangZhou['dependent'] = guangDong;
// 广东无需单独保存,因为在保存广州时自动保存了广东
await guangZhou.save();
// 新建一个 AV.Object
const GuangZhou = new AV.Object('City');
GuangZhou.set('name', '广州');
const GuangDong = new AV.Object('Province');
GuangDong.set('name', '广东');
GuangZhou.set('dependent', GuangDong);
GuangZhou.save().then(function (guangZhou) {
// 广州、广东保存成功(广东无需单独保存)
console.log(guangZhou.id);
});
guang_zhou = leancloud.Object.extend('City')()
guang_zhou.set('name', '广州')
guang_dong = leancloud.Object.extend('Province')()
guang_dong.set('name', '广东')
guang_zhou.set('dependent', guang_dong)
# 广东无需单独保存,因为在保存广州时自动保存了广东
guang_zhou.save()
$guangZhou = new LeanObject("City");
$guangZhou->set("name", "广州");
$guangDong = new LeanObject("Province");
$guangDong->set("name", "广东");
$guangZhou->set("dependent", $guangDong);
// 广东无需单独保存,因为在保存广州时自动保存了广东
$guangZhou->save();
保存关联对象的同时,被关联的对象也会随之被保存到云端。
执行上述代码后,在应用控制台可以看到 dependent 字段显示为 Pointer 数据类型,而它本质上存储的是一个指向 Province 这张表的某个 AVObject 的指针。
要关联一个已经存在于云端的对象,例如将「东莞市」添加至「广东省」(假设广东的 objectId 为 56545c5b00b09f857a603632),方法如下:
- .NET
- Java
- Objective-C
- Swift
- Flutter
- JavaScript
- Python
- PHP
- Go
LCObject guangDong = LCObject.CreateWithoutData("Province", "56545c5b00b09f857a603632");
LCObject dongGuan = new LCObject("City");
dongGuan["name"] = "东莞";
AVObject guangDong = AVObject.createWithoutData("Province", "56545c5b00b09f857a603632");
AVObject dongGuan = new AVObject("City");
dongGuan.put("name", "东莞");
dongGuan.put("dependent", guangDong);
LCObject *GuangDong = [LCObject objectWithClassName:@"Province" objectId:@"56545c5b00b09f857a603632"];
LCObject *DongGuan = [LCObject objectWithClassName:@"City"];
[DongGuan setObject:@"东莞" forKey:@"name"];
[DongGuan setObject:GuangDong forKey:@"dependent"];
let guangDong = LCObject(className: "Province", objectId: "56545c5b00b09f857a603632")
let dongGuan = LCObject(className: "City")
try dongGuan.set("name", value:"东莞")
dongGuan["dependent"] = guangDong
LCObject guangDong = LCObject.createWithoutData('Province', '56545c5b00b09f857a603632');
LCObject DongGuan = LCObject('City');
DongGuan['name'] = '东莞';
DongGuan['dependent'] = guangDong;
const GuangDong = AV.Object.createWithoutData('Province', '56545c5b00b09f857a603632');
const DongGuan = new AV.Object('City');
DongGuan.set('name', '东莞');
DongGuan.set('dependent', GuangDong);
Province = leancloud.Object.extend('Province')
guang_dong = Province.create_without_data('574416af79bc44005c61bfa3')
dong_guan = leancloud.Object.extend('City')()
dong_guan.set('name', '东莞')
dong_guan.set('dependent', guang_dong)
$guangDong = LeanObject::create("Province", "574416af79bc44005c61bfa3");
$dongGuan = new LeanObject("City");
$dongGuan->set("name", "东莞");
$dongGuan->set("dependent", $guangDong);
注意,为了节约篇幅,以上代码中省略了保存对象的代码。
Pointers 查询
想知道广州属于哪个省份:
- .NET
- Java
- Objective-C
- Swift
- Flutter
- JavaScript
- Python
- PHP
- Go
LCQuery<LCObject> query = new LCQuery<LCObject>("City");
// 查询名字是广州的城市
query = query.WhereEqualTo("name", "广州");
// 告知云端还要一并获取对应城市的省份
query = query.Include("dependent");
LCObject city = await query.First();
LCObject province = city["dependent"] as LCObject;
AVQuery<AVObject> query = new AVQuery<>("City");
query.whereEqualTo("name", "广州");
query.include("dependent");
query.getFirstInBackground().subscribe(new Observer<AVObject>() {
public void onSubscribe(Disposable disposable) {}
public void onNext(List<AVObject> city) {
AVObject province = city.getAVObject("dependent");
}
public void onError(Throwable throwable) {}
public void onComplete() {}
});
LCQuery *query = [LCQuery queryWithClassName:@"City"];
[query whereKey:@"name" equalTo:@"广州"];
[query includeKey:@"dependent"];
[query getFirstObjectInBackgroundWithBlock:^(LCObject *city, NSError *error) {
LCObject *province = [city objectForKey:@"dependent"];
}];
let query = LCQuery(className: "City")
query.whereKey("name", .equalTo: "广州")
query.whereKey("dependent", .included)
_ = query.getFirst { result in
switch result {
case .success(object: let city):
let province = city["dependent"] as? LCObject
case .failure(error: let error):
print(error)
}
}
LCQuery<LCObject> query = LCQuery('City');
query.whereEqualTo('name', '广州');
query.include('dependent');
LCObject city = await query.First();
LCObject province = city['dependent'];
const query = new AV.Query('City');
query.equalTo('name', '广州');
query.include(['dependent']);
query.first().then((city) => {
const province = city.get('dependent');
});
query = leancloud.Query("City")
query.equal_to('name', '广州')
query.include('dependent')
city = query.first()
province = city.get('dependent')
$query = new Query("City");
$query->equalTo("name", "广州");
$query->_include("dependent");
$city = $query->first();
$province = $city->get("dependent");
想知道哪些城市属于广东省(假定代表广东省的对象的 objectId 是 56545c5b00b09f857a603632) ?
- .NET
- Java
- Objective-C
- Swift
- Flutter
- JavaScript
- Python
- PHP
- Go
LCObject guangDong = LCObject.CreateWithoutData("Province", "56545c5b00b09f857a603632");
LCQuery<LCObject> query = new LCQuery<LCObject>("City");
query.WhereEqualTo("dependent", guangDong);
// cities 为广东省下辖的所有城市
ReadOnlyCollection<LCObject> cities = await query.Find();
AVObject guangDong = AVObject.createWithoutData("Province", "56545c5b00b09f857a603632");
AVQuery<AVObject> query = new AVQuery<>("City");
query.whereEqualTo("dependent", guangDong);
query.findInBackground().subscribe(new Observer<List<AVObject>>() {
@Override
public void onSubscribe(Disposable d) {}
@Override
public void onNext(List<AVObject> cities) {
for (AVObject city : cities) {
// cities 为广东省下辖的所有城市
}
}
@Override
public void onError(Throwable e) {}
@Override
public void onComplete() {}
});
LCObject *GuangDong = [LCObject objectWithClassName:@"Province" objectId:@"56545c5b00b09f857a603632"];
LCQuery *query = [LCQuery queryWithClassName:@"City"];
[query whereKey:@"dependent" equalTo:GuangDong];
[query findObjectsInBackgroundWithBlock:^(NSArray *cities, NSError *error) {
for (LCObject *city in cities) {
// cities 为广东省下辖的所有城市
}
}];
let guangDong = LCObject(className: "Province", objectId: "56545c5b00b09f857a603632")
let query = LCQuery(className: "City")
query.whereKey("dependent", .equalTo(GuangDong))
_ = query.find { (result) in
switch result {
case .success(objects: let cities):
for city in cities {
// cities 为广东省下辖的所有城市
}
case .failure(error: let error):
print(error)
}
}
LCObject guangDong = LCObject.createWithoutData('Province', '56545c5b00b09f857a603632');
LCQuery<LCObject> query = LCQuery('City');
query.whereEqualTo('dependent', guangDong);
// cities 为广东省下辖的所有城市
List<LCObject> cities = await query.find();
const GuangDong = AV.Object.createWithoutData('Province', '56545c5b00b09f857a603632');
const query = new AV.Query('City');
query.equalTo('dependent', GuangDong);
query.find().then((cities) => {
// cities 为广东省下辖的所有城市
});
Province = leancloud.Object.extend('Province')
guang_dong = Province.create_without_data('574416af79bc44005c61bfa3')
query = leancloud.Query('City')
query.equal_to('dependent', guang_dong)
# cities 为广东省下辖的所有城市
cities = query.find():
$guangDong = LeanObject::create("Province", "574416af79bc44005c61bfa3");
$query = new Query("City");
$query->equalTo("dependent", $guangDong);
// cities 为广东省下辖的所有城市
$cities = $query->find();
大多数场景下,Pointers 是实现一对多关系的最好选择。
多对多关系
假设有选课应用,我们需要为 Student 对象和 Course 对象建模。一个学生可以选多门课程,一个课程也有多个学生,这是一个典型的多对多关系。我们必须使用 Arrays 或创建自己的中间表来实现这种关系。决策的关键在于是否需要为这个关系附加一些属性。
如果不需要附加属性,使用 Arrays 最为简单。通常情况下,使用 Arrays 可以使用更少的查询并获得更好的性能。
如果多对多关系中任何一方对象数量可能达到或超过 100,使用中间表是更好的选择。
反之,若需要为关系附加一些属性,就创建一个独立的表(中间表)来存储两端的关系。记住,附加的属性是描述这个关系的,不是描述关系中的任何一方。所附加的属性可以是:
- 关系创建的时间
- 关系创建者
- 某人查看此关系的次数
使用中间表实现多对多关系(推荐)
有时我们需要知道更多关系的附加信息,比如在一个学生选课系统中,我们要了解学生打算选修的这门课的课时有多长,或者学生选修是通过手机选修还是通过网站操作的,此时我们可以使用传统的数据模型设计方法「中间表」。
为此,我们创建一个独立的表 StudentCourseMap 来保存 Student 和 Course 的关系:
| 字段 | 类型 | 说明 |
|---|---|---|
course | Pointer | Course 指针实例 |
student | Pointer | Student 指针实例 |
duration | Array | 所选课程的开始和结束时间点,如 ["2016-02-19","2016-04-21"]。 |
platform | String | 操作时使用的设备,如 iOS。 |
如此,实现选修功能的代码如下:
- .NET
- Java
- Objective-C
- Swift
- Flutter
- JavaScript
- Python
- PHP
- Go
LCObject studentTom = new LCObject("Student");
studentTom["name"] = "Tom";
LCObject courseLinearAlgebra = new LCObject("Course");
courseLinearAlgebra["name"] = "线性代数";
LCObject studentCourseMapTom = new LCObject("StudentCourseMap");
// 设置关联
studentCourseMapTom["student"] = studentTom;
studentCourseMapTom["course"] = courseLinearAlgebra;
// 设置学习周期
studentCourseMapTom["duration"] = new string[] { "2016-02-19", "2016-04-21" });
// 获取操作平台
studentCourseMapTom["platform"] = "iOS";
// 保存选课表对象
await studentCourseMapTom.Save();
AVObject studentTom = new AVObject("Student");
studentTom.put("name", "Tom");
AVObject courseLinearAlgebra = new AVObject("Course");
courseLinearAlgebra.put("name", "线性代数");
AVObject studentCourseMapTom = new AVObject("StudentCourseMap");
// 设置关联
studentCourseMapTom.put("student", studentTom);
studentCourseMapTom.put("course", courseLinearAlgebra);
// 设置学习周期
studentCourseMapTom.put("duration", Arrays.asList("2016-02-19", "2016-04-21"));
// 获取操作平台
studentCourseMapTom.put("platform", "iOS");
// 保存选课表对象
studentCourseMapTom.saveInBackground().subscribe(new Observer<AVObject>() {
public void onSubscribe(Disposable disposable) {}
public void onNext(AVObject studentCourseMapTom) {
// 成功保存之后,执行其他逻辑
}
public void onError(Throwable throwable) {
// 异常处理
}
public void onComplete() {}
});
LCObject *studentTom = [LCObject objectWithClassName:@"Student"];
[studentTom setObject:@"Tom" forKey:@"name"];
LCObject *courseLinearAlgebra = [LCObject objectWithClassName:@"Course"];
[courseLinearAlgebra setObject:@"线性代数" forKey:@"name"];
LCObject *studentCourseMapTom = [LCObject objectWithClassName:@"StudentCourseMap"];
// 设置关联
[studentCourseMapTom setObject:studentTom forKey:@"student"];
[studentCourseMapTom setObject:courseLinearAlgebra forKey:@"course"];
// 设置学习周期
[studentCourseMapTom setObject:[NSArray arrayWithObjects:@"2016-02-19",@"2016-04-21", nil] forKey:@"duration"];
// 获取操作平台
[studentCourseMapTom setObject:@"iOS" forKey:@"platform"];
// 保存选课表对象
[studentCourseMapTom saveInBackgroundWithBlock:^(BOOL succeeded, NSError *error) {
if (succeeded) {
// 成功保存之后,执行其他逻辑
} else {
// 异常处理
}
}];
do {
let studentTom = LCObject(className: "Student")
try studentTom.set("name", value: "Tom")
let courseLinearAlgebra = LCObject(className: "Course")
try courseLinearAlgebra.set("name"), value: "线性代数")
let studentCourseMapTom = LCObject(className: "StudentCourseMap")
try studentCourseMapTom.set("student", value: studentTom)
try studentCourseMapTom.set("course", value: courseLinearAlgebra)
try studentCourseMapTom.set("duration", value: ["2016-02-19", "2016-04-21"])
try studentCourseMapTom.set("platform", value: "iOS")
_ = studentCourseMapTom.save { result in
switch result {
case .success:
break
case .failure(error: let error):
print(error)
}
}
} catch {
print(error)
}
LCObject studentTom = LCObject('Student');
studentTom['name'] = 'Tom';
LCObject courseLinearAlgebra = LCObject('Course');
courseLinearAlgebra['name'] = '线性代数';
LCObject studentCourseMapTom = LCObject('StudentCourseMap');
// 设置关联
studentCourseMapTom['student'] = studentTom;
studentCourseMapTom['course'] = courseLinearAlgebra;
// 设置学习周期
studentCourseMapTom['duration'] = ['2016-02-19', '2016-04-21'];
// 获取操作平台
studentCourseMapTom['platform'] = 'iOS';
// 保存选课表对象
await studentCourseMapTom.save();
const studentTom = new AV.Object('Student');
studentTom.set('name', 'Tom');
const courseLinearAlgebra = new AV.Object('Course');
courseLinearAlgebra.set('name', '线性代数');
const studentCourseMapTom = new AV.Object('StudentCourseMap');
// 设置关联
studentCourseMapTom.set('student', studentTom);
studentCourseMapTom.set('course', courseLinearAlgebra);
// 设置学习周期
studentCourseMapTom.set('duration', ["2016-02-19", "2016-04-12"]);
// 设置操作平台
studentCourseMapTom.set('platform', 'web');
// 保存选课表对象
studentCourseMapTom.save().then((studentCourseMapTom) => {
// 成功保存之后,执行其他逻辑
console.log(`保存成功。objectId:${todo.id}`);
}, (error) => {
// 异常处理
});
student_tom = leancloud.Object.extend('Student')()
student_tom.set('name', 'Tom')
course_linear_algebra = leancloud.Object.extend('Course')()
course_linear_algebra.set('name', '线性代数')
student_course_map_tom = leancloud.Object.extend('Student_course_map')()
# 设置关联
student_course_map_tom.set('student', student_tom)
student_course_map_tom.set('course', course_linear_algebra)
# 设置学习周期
student_course_map_tom.set('duration', ["2016-02-19", "2016-04-12"])
# 设置操作平台
student_course_map_tom.set('platform', 'ios')
# 保存选课表对象
student_course_map_tom.save()
$studentTom = new LeanObject("Student");
$studentTom->set("name", "Tom");
$courseLinearAlgebra = new LeanObject("Course");
$courseLinearAlgebra->set("name", "线性代数");
$studentCourseMapTom = new LeanObject("StudentCourseMap");
// 设置关联
$studentCourseMapTom->set("student", $studentTom);
$studentCourseMapTom->set("course", $courseLinearAlgebra);
// 设置学习周期
$studentCourseMapTom->set("duration", array("2016-02-19", "2016-04-12"));
// 设置操作平台
$studentCourseMapTom->set("platform", "ios");
// 保存选课表对象
$studentCourseMapTom->save();
查询选修了某一课程的所有学生:
- .NET
- Java
- Objective-C
- Swift
- Flutter
- JavaScript
- Python
- PHP
- Go
// 线性代数课程
LCObject courseLinearAlgebra = LCObject.CreateWithoutData("Course", "562da3fdddb2084a8a576d49");
// 构建 StudentCourseMap 的查询
LCQuery<LCObject> query = new LCQuery<LCObject>("StudentCourseMap");
// 查询所有选择了线性代数的学生
query.WhereEqualTo("course", courseLinearAlgebra);
ReadOnlyCollection<LCObject> studentCourseMaps = await query.Find();
foreach (var studentCourseMap in studentCourseMaps)
{
LCObject student = studentCourseMap["student"] as LCObject;
List<string> duration = studentCourseMap["duration"] as List<string>;
string platform = studentCourseMap["platform"] as string;
}
// 线性代数课程
AVObject courseLinearAlgebra = AVObject.createWithoutData("Course", "562da3fdddb2084a8a576d49");
// 构建 StudentCourseMap 的查询
AVQuery<AVObject> query = new AVQuery<>("StudentCourseMap");
// 查询所有选择了线性代数的学生
query.whereEqualTo("course", courseLinearAlgebra);
// 执行查询
query.findInBackground().subscribe(new Observer<List<AVObject>>() {
@Override
public void onSubscribe(Disposable d) {
}
@Override
public void onNext(List<AVObject> list) {
// list 是所有 course 等于线性代数的选课对象
// 然后遍历过程中可以访问每一个选课对象的 student,course,duration,platform 等属性
for (AVObject studentCourseMap : list) {
AVObject student = studentCourseMap.getAVObject("student");
ArrayList duration = (ArrayList) studentCourseMap.getList("duration");
String platform = studentCourseMap.getString("platform");
}
}
@Override
public void onError(Throwable e) {
}
@Override
public void onComplete() {
}
});
// 线性代数课程
LCObject *courseLinearAlgebra = [LCObject objectWithClassName:@"Course" objectId:@"562da3fdddb2084a8a576d49"];
// 构建 StudentCourseMap 的查询
LCQuery *query = [LCQuery queryWithClassName:@"StudentCourseMap"];
// 查询所有选择了线性代数的学生
[query whereKey:@"course" equalTo:courseLinearAlgebra];
// 执行查询
[query findObjectsInBackgroundWithBlock:^(NSArray *studentCourseMaps, NSError *error) {
// studentCourseMaps 是所有 course 等于线性代数的选课对象
// 然后遍历过程中可以访问每一个选课对象的 student,course,duration,platform 等属性
for (LCObject *studentCourseMap in studentCourseMaps) {
LCObject *student =[studentCourseMap objectForKey:@"student"];
NSArray *duration = [studentCourseMap objectForKey:@"duration"];
NSLog(@"platform: %@", [studentCourseMap objectForKey:@"platform"]);
}
}];
let query = LCQuery(className: "StudentCourseMap")
let courseLinearAlgebra = LCObject(className: "Course", objectId: "562da3fdddb2084a8a576d49")
query.whereKey("course", equalTo: courseLinearAlgebra)
_ = query.find { (result) in
switch result {
case .success(objects: let studentCourseMaps):
for studentCourseMap in studentCourseMaps {
let student = studentCourseMap["student"] as? LCObject
let duration = studentCourseMap["duration"] as? LCArray
let platform = studentCourseMap["platform"] as? LCString
}
case .failure(error: let error):
print(error)
}
}
// 线性代数课程
LCObject courseLinearAlgebra = LCObject.createWithoutData('Course', '562da3fdddb2084a8a576d49');
// 构建 StudentCourseMap 的查询
LCQuery<LCObject> query = LCQuery('StudentCourseMap');
// 查询所有选择了线性代数的学生
query.whereEqualTo('course', courseLinearAlgebra);
List<LCObject> list = await query.find();
// list 是所有 course 等于线性代数的选课对象
// 然后遍历过程中可以访问每一个选课对象的 student,course,duration,platform 等属性
for (LCObject studentCourseMap in list) {
LCObject student = studentCourseMap['student'];
LCObject course = studentCourseMap['course'];
List<String> duration = studentCourseMap['duration'];
String platform = studentCourseMap['platform'];
}
// 线性代数课程
const courseLinearAlgebra = AV.Object.createWithoutData('Course', '562da3fdddb2084a8a576d49');
// 构建 StudentCourseMap 的查询
const query = new AV.Query('StudentCourseMap');
// 查询所有选择了线性代数的学生
query.equalTo('course', courseLinearAlgebra);
// 执行查询
query.find().then(function (studentCourseMaps) {
// studentCourseMaps 是所有 course 等于线性代数的选课对象
// 然后遍历过程中可以访问每一个选课对象的 student,course,duration,platform 等属性
studentCourseMaps.forEach(function (scm, i, a) {
const student = scm.get('student');
const duration = scm.get('duration');
const platform = scm.get('platform');
});
});
Course = leancloud.Object.extend('Course')
course_linear_algebra = Course.create_without_data('57448184c26a38006b8d4761')
query = leancloud.Query('Student_course_map')
query.equal_to('course', course_linear_algebra)
# 查询所有选择了线性代数的学生
student_course_map_list = query.find()
# list 是所有 course 等于线性代数的选课对象,
# 然后遍历过程中可以访问每一个选课对象的 student,course,duration,platform 等属性
for student_course_map in student_course_map_list:
student = student_course_map.get('student')
duration = student_course_map.get('duration')
platform = student_course_map.get('platform')
$courseLinearAlgebra = LeanObject::create("Course", "57448184c26a38006b8d4761");
$query = new Query("Student_course_map");
$query->equalTo("course", $courseLinearAlgebra);
// 查询所有选择了线性代数的学生
$studentCourseMaps = $query->find();
foreach ($studentCourseMaps as $studentCourseMap) {
$student = $studentCourseMap->get("student");
$duration = $studentCourseMap->get("duration");
$platform = $studentCourseMap->get("platform");
}
同样我们也可以很简单地查询某一个学生选修的所有课程,只需将上述代码变换查询条件即可:
- .NET
- Java
- Objective-C
- Swift
- Flutter
- JavaScript
- Python
- PHP
- Go
LCQuery *query = [LCQuery queryWithClassName:@"StudentCourseMap"];
LCObject *studentTom = [LCObject objectWithClassName:@"Student" objectId:@"562da3fc00b0bf37b117c250"];
[query whereKey:@"student" equalTo:studentTom];
let query = LCQuery(className: "StudentCourseMap")
let studentTom = LCObject(className: "Student", objectId: "562da3fc00b0bf37b117c250")
query.whereKey("student", equalTo: studentTom)
AVQuery<AVObject> query = new AVQuery<>("StudentCourseMap");
AVObject studentTom = AVObject.createWithoutData("Student", "562da3fc00b0bf37b117c250");
query.whereEqualTo("student", studentTom);
const studentTom = AV.Object.createWithoutData('Student', '579f0441128fe10054420d49');
const query = new AV.Query('StudentCourseMap');
query.equalTo('student', studentTom);
Student = leancloud.Object.extend('Student')
student_tom = Student.create_without_data("562da3fc00b0bf37b117c250")
query.whereEqualTo("student", student_tom)
$studentTom = LeanObject::create("Student", "562da3fc00b0bf37b117c250");
$query->equalTo("student", $studentTom);
LCQuery<LCObject> query = new LCQuery<LCObject>("StudentCourseMap");
LCObject studentTom = LCObject.CreateWithoutData("Student", "562da3fc00b0bf37b117c250");
query.WhereEqualTo("student", studentTom);
LCQuery<LCObject> query = LCQuery('StudentCourseMap');
LCObject studentTom = LCObject.createWithoutData('Student', '562da3fc00b0bf37b117c250');
query.whereEqualTo('student', studentTom);
我们在上面的代码中省略了执行查询的语句,以节省篇幅。
一对一关系
当你需要将一个对象拆分成两个对象时,一对一关系是一种重要的需求,例如:
限制部分用户数据的权限
在这个场景中,你可以将此对象拆分成两部分,一部分包含所有用户可见的数据,另一部分包含所有仅自己可见的数据(通过 ACL 控制 )。同样你也可以实现一部分包含所有用户可修改的数据,另一部分包含所有仅自己可修改的数据。
避免大对象
原始对象大小超过了对象的 128 KB 的上限值,此时你可以创建另一个对象来存储额外的数据。当然通常的作法是更好地设计和优化数据模型来避免出现大对象,但如果确实无法避免,则可以考虑使用 AVFile 存储大数据。
更灵活的文件对象
AVFile 可以方便地存取文件,但对对象进行查询和修改等操作就不是很方便了。此时可以使用 AVObject 构造一个自己的文件对象并与 AVFile 建立一对一关联,将文件属性存于 AVObject 中,这样既可以方便查询修改文件属性,也可以方便存取文件。
关联数据的删除
当表中有一个 Pointer 指向的源数据被删除时,这个源数据对应的 Pointer 不会被自动删除。所以建议用户在删除源数据时自行检查是否有 Pointer 指向这条数据,基于业务场景有必要做数据清理的话,可以调用对应的对象上的删除接口将 Pointer 关联的对象删除。
索引
在任何一个数据库系统中,索引都是优化性能的重要手段,同时它与 Schema 设计也是密不可分的。LeanCloud 数据存储也支持索引,其索引与关系数据库中基本相同。在索引的选择上,应用查询操作的模式和频率起决定性作用。
同时也要注意,索引不是没有代价的。在加速查询的同时,它也会降低写入速度、消耗更多存储空间。是否建索引,如何建索引,建多少索引,我们需要综合权衡后来下决定。
索引类型
数据存储的索引可以包含任意的属性(包括数组),下面是一些索引选项:
复合索引
在多个属性域上构建一个单独的索引结构。例如,以一个存储客户数据的应用为例,我们可能需要根据姓、名和居住地来查询客户信息。通过在「姓、名、居住地」上建立复合索引,LeanCloud 可以快速给出满足这三个条件的结果。此外,这一复合索引也能加速任何前置属性的查询。例如根据「姓」或者根据「姓+名」的查询都会使用到这个复合索引。
注意,如果单按照「名」来查询,此复合索引会失效。
唯一索引
通过给索引加上唯一性约束,LeanCloud 就会拒绝含有相同索引值的对象插入和更新。所有的索引默认都不是唯一索引,如果把复合索引指定为唯一索引,那么应用层必须保证索引列的组合值是唯一的。
数组索引
对数组属性也能创建索引。
地理空间索引
LeanCloud 会自动为 GeoPoint 类型的属性建立地理空间索引,但是要求一个 Object 内 GeoPoint 的属性不能超过一个。稀疏索引
这种索引只包含那些含有指定属性的文档,如果文档不含有目标属性,那么就不会进入索引。稀疏索引体积更小,查询性能更高。LeanCloud 数据存储默认都会创建稀疏索引。
LeanCloud 数据存储的索引可以在任何域上建立,包括内嵌对象和数组类型,这使它带来了比 RDBMS 更强大的功能。通过索引优化性能
LeanCloud 后台会根据每天的访问日志,自动归纳和学习频繁使用的访问模式,并自动创建合适的索引。不过如果你对索引优化比较有经验,也可以在控制台为每一个 Class 手动创建索引。持续优化 Schema
在 LeanCloud 的存储系统里,Class 可以在没有完整的结构定义(包含哪些属性、数据类型如何等)时就提前创建好,一个 Class 下的对象(Object)也无需包含所有属性域,我们可以随时往对象中增减新的属性。
这种灵活、动态的 Schema 机制,使 Schema 的持续优化变得非常简单。相比之下,关系数据库的开发人员和 DBA 在开始一个新项目的时候,写下第一行代码之前,就需要制定好数据库 Schema,这至少需要几天,有的需要数周甚至更长。而 LeanCloud 则允许开发者通过不断迭代和敏捷过程,持续优化 Schema。开发者可以开始写代码并将他们创建的对象持久化存储起来,以后当需要增加新的功能,LeanCloud 可以继续存储新的对象而不需要对原来的 Class 做 ALTER TABLE 操作,这会给我们的开发带来很大的便利。
最佳的建模方式
选择最适合的建模方式,首先要确定关系是否:
存在附加属性?
例如学生选课,学生在选课的时候有的从电脑浏览器里选,有的从手机上选,手机系统还区分 iOS、Android 等等。那么假设要统计一下学生选课的来源,那么建立选课关系的时候就需要记录一下附加属性,这时只有中间表可以满足这个需求。
其次判断:
是一对多还是多对多?
- 一对多:Pointer
- 多对多:中间表
决定了用哪种方式之后,就按照前文介绍的一对多或多对多的实例代码构建自己的业务逻辑代码。但是 Pointer 可以实现的,中间表也可以实现,并且开发者可控的余地更多。具体可以参照如下伪代码:
if(存在附加属性){
return 中间表;
} else {
switch(mode){
case 一对多:{
return Pointer;
}
case 多对多:{
return 中间表;
}
}
}
案例分析
婴儿与监护人之间的关系
做一个应用统计婴儿吃饭、睡觉、玩耍的时间分布,而婴儿的监护人可能会有多个,爷爷奶奶外公外婆还有可能是月嫂。首先按照我们之前设定的思路来逐步分析应该采用哪种方式建模:
是否存在附加属性?
一个婴儿和一个监护人之间的关系是否有附加属性?答案是有附加属性,父子关系跟母子关系是不一样的关系,因为对于婴儿监护人的身份称呼就是这个关系的附加属性。因此不用多想,果断使用中间表。不用再纠结是一对多还是多对多。

用户与设备之间的关系
婴儿的状态改变,可以通过推送服务做到实时推送给监护人,比如孩子的爸爸设备较多,他会在 iPad、iPhone 以及 Windows 上安装这个应用,那么他一般情况下会有 3 台设备。监护人在每一台设备上登录后,每当孩子的状态发生改变,服务端都会向这 3 台设备推送,那么我们接着按照之前的思路来分析应该采用哪种方式建模。
是否存在附加属性?
一般来说这种情况是可以省略附加属性的,因为 LeanCloud 的 _Installation 表里有一个字段是专门用来存储客户端设备的 deviceType,因此设备的信息是不需要存储在中间表的。
而除非有其他特殊的属性条件,设备和用户之间的关系就是一个简单的一对多的关系,并且并不需要附加属性。
其次判断:
是一对多还是多对多?
一个用户在多个设备上登录一般就可以定义为一对多,而很少会出现类似 iPhone/iPad 版 QQ 那样内置了多账户管理系统,因此定义为一对多比较满足我们现在的需求。
何时使用数组
当要关联的数据是简单数据并且查询多于修改的时候,用数组比较合适。比如社交类应用里给朋友加标签,就可以使用 string 数组来存储这个属性。
- .NET
- Java
- Objective-C
- Swift
- Flutter
- JavaScript
- Python
- PHP
- Go
LCObject beckham = new LCObject("Boy");
beckham["tags"] = new string[] { "颜值爆表", "明星范儿" });
AVObject beckham = new AVObject("Boy");
beckham.put("tags", Arrays.asList("颜值爆表", "明星范儿"));
LCObject *beckham = [LCObject objectWithClassName:@"Boy"];
[beckham setObject: [NSArray arrayWithObjects:@"颜值爆表",@"明星范儿",nil] forKey:@"tags"];
let beckham = LCObject(className: "Boy")
try beckham.set("tags", value: ["颜值爆表", "明星范儿"])
LCObject beckham = LCObject('Boy');
beckham['tags'] = ['颜值爆表', '明星范儿'];
const beckham = new AV.Object('Boy');
beckham.set('tags', ['颜值爆表','明星范儿']);
beckham = leancloud.Object.create('Boy')()
beckham.set('tags', ['颜值爆表', '明星范儿'])
$beckham = new LeanObject("Boy");
$beckham->set("tags", array("颜值爆表", "明星范儿"));
为节省篇幅,上面的代码省略了保存对象的语句。
数组过长可能会影响性能,建议数组长度控制在 1000 以下。 数组长度达到 10000 后,云端会拒绝向数组追加元素的请求。